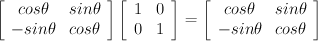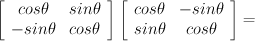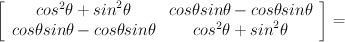Refections on experiences with programming languages...It's a familiar story. A kid in the 80s stumbles upon a TRS-80, an Apple II or an Atari 800, opens to the "Hello World" page of the manual, and the rest is history. It's my story too. Programming, the way it began.
As far as languages go, unsurprisingly, BASIC was first. I was another one of those kids tapping away on an Atari computer. My brother and I had a simple game up and running on the first day. I could reflect on experiences with my first computer to great length, but this post is about programming languages, so I'll carry on.
Subsequent experiences with programming languages ranged from dabblings to wholesale conversions. Some experiences were the result of assigned classwork. Other experiences came in response to needs and curiosities.
I had access to a timesharing system in high school, which offered me the chance to experiment with several languages the system supported: BASIC, Pascal,
Snobol, Fortran, etc.
Fortran? It was worthy of experimentation, but not without its irritations (like syntax determined by whitespace, a phenomenon for which there's
absolutely no excuse nowadays!).
As far as languages beginning with the letters F-O-R go, there was also
Forth. I purchased a copy for my Atari and spent quite a bit of time playing with it. I didn't know it at the time, but it helped prepare me for later work with PostScript.
A desire to create better video games led me into the world of 6502 assembly language. It was the only way to get the speed. There's something immensely satisfying about working in assembly language, especially to those who enjoy puzzles and challenges--breaking higher concepts down into primitive bit-twiddling instructions, getting right down to the metal, honing the inner loops, watching each step of the cpu's gears.
Experience with Pascal eventually translated into a wholesale conversion--it became my language of choice, largely due to
Turbo Pascal, Borland's fast and fine compiler at the time. In terms of structure and performance it was an enormous improvement over BASIC.
After playing around with a half a dozen languages in high school, college offered me fewer surprises than I expected. I developed a great admiration for
Lisp. Several of my courses used it, and I did quite a bit of recreational programming in it as well. Of all the languages I learned in college, it was the most mind expanding.
My appreciation for it generated many shrugs over the years, and I offer thanks to Paul Graham for making it cool to be a Lisp aficionado. :)
Cobol? Cursed Cobol. It was a class so mind-numbing and tedious I wrote a code generator for it. Rather than plunking in the Cobol to generate fictitious corporate reports, I plunked in a sample report and let the code generator spew out the pages of carefully spaced Cobol needed to generate it. It saved me hours and hours of work in a single class. Ugh!
Aside from Lisp, another college language that left a significant impact on me was
Ada. I still retain a good deal of respect for the language. It had nice support for object-oriented programming, generic programming, type safety, multi-threading. For a long time, it was a point of reference in the critique of languages arriving afterwards.
Other languages learned in college include x86 assembly language, something I still use when needed.
Prolog was interesting, and it offered interesting insights, but I never found any use for it professionally. I also enjoyed playing with a language called
Rexx. Unfortunately, I never ran into
Smalltalk in college, and as far as omissions go, this one is most unfortunate.
C eventually replaced Pascal as my language of choice. After that, it was C++ as soon as Borland's
Turbo C++ became available.
And then there's Java, Javascript, Python, PHP and other languages resulting from the rise of the Internet.
Insights and conclusions? This is something I'm going to be thinking about in greater depth.
A longtime friend and ex-colleague of mine is still a language fiend by my estimation. From his perspective, I'm a "
syntactic sugar" guy, meaning I see many hailed improvements in programming languages as mere refinements in syntax rather than more desirable substantial improvements.
As far as metaphors go, I prefer "rearranging the syntactic furniture":
"Oh, let's put that over here now!"
"Why?"
"It will be fun!"
What's most frustrating is that many alleged improvements in new languages appear to be steps backward; especially syntax determined by white space, which strikes me as the geek equivalent of bringing back bad fashion ideas from the 70s and 80s. Pet rock, anyone?
I need to think about this more...